We present two Qwen models taught to predict various nuances in spontaneous dialogue by reconstructing conversational disfluencies and transcript-level prosodic cues from simplified dialogue transcripts.
Rather than attempting to construct realistic conversational dialogue in one shot, we focused on the simpler objective of recovering the complex interactional structure and messiness of human conversation from a vanilla, bare bones transcript of the conversation as a guide, thereby teaching our models to predict where to place nuanced dialogue elements and generate more realistic conversational flow. These include filler words, overlap, backchannels, interruptions, partial words, laughter, and self correction.
Both models were trained with the same direct reconstruction objective using a limited 100 conversation dataset (CallHome_Eng). However, the second was trained with additional reasoning traces in order to help it place cues and shape the conversation more deliberately. On a matched 20-conversation held-out set (with the same prompted objective of reconstructing the ground truth transcript from a simplified dialogue architecture), both models beat zero-shot GPT-4o on 19 of 20 conversations, and the reasoning model reduces average feature error by 34.7%.
As a note, here, "prosody" refers to transcript-visible timing and floor-management cues rather than acoustic pitch contours alone. The models are not generating audio directly. They are reconstructing the textual substrate that downstream speech systems can condition on or realize.
Why this matters
Synthetic speech quality often bottlenecks earlier than people expect. The waveform can sound polished while the transcript underneath still looks too clean, too linear, and too written. If that substrate is wrong, downstream systems inherit the wrong rhythm. This is a significant problem found in most synthetic pipelines which tend to generate full conversational transcripts from one LLM pass, resulting in dialogues lacking the convoluted flow, overlap, and disfluencies of real speech.
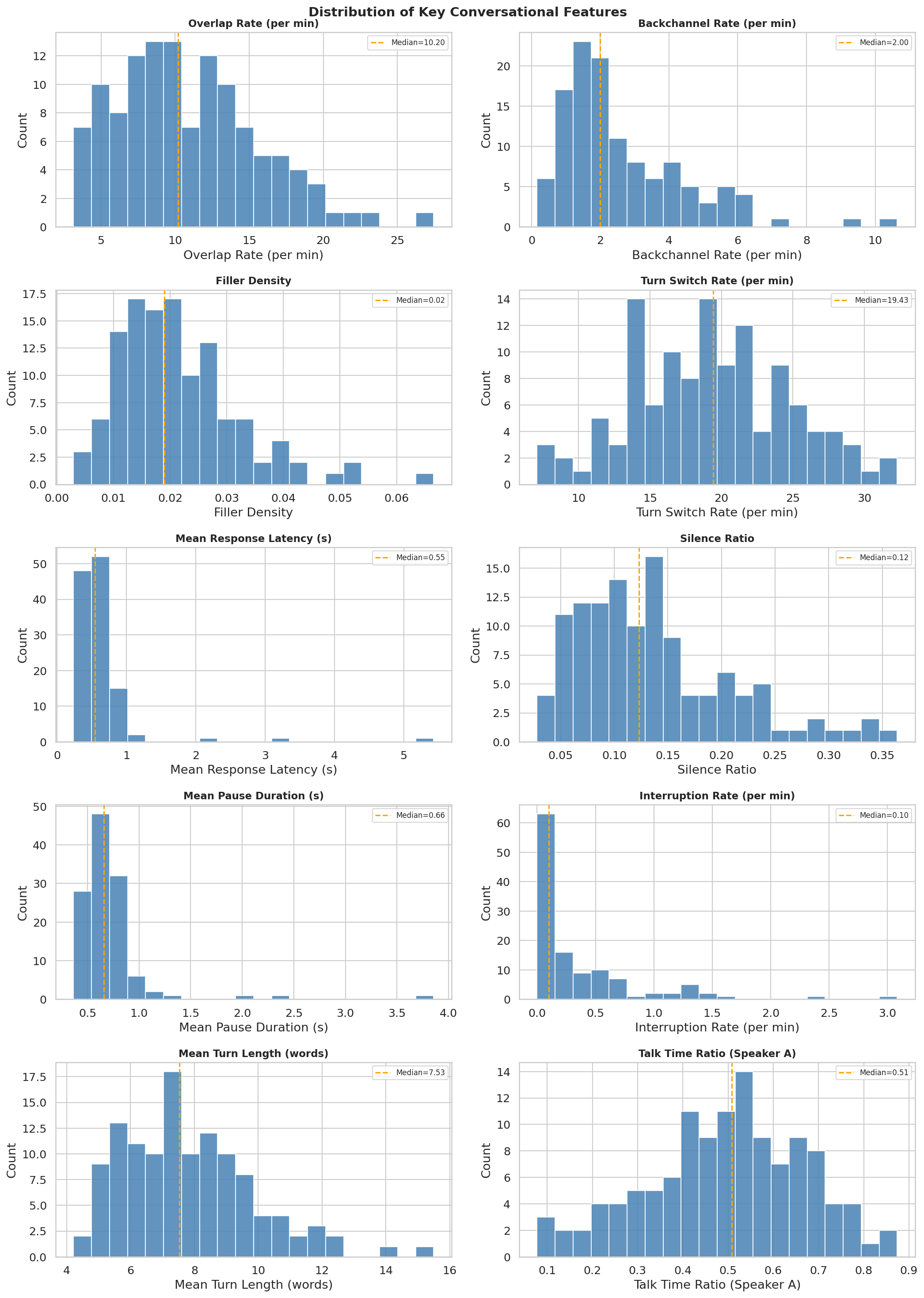
We begin by measuring real world distribution of various disfluencies and dialogue patterns found in real world conversation transcripts. In a full 120-conversation CallHome analysis, overlap ranges from 3.1 to 27.4 events per minute, backchannels from 0.16 to 10.64 per minute, filler density from 0.003 to 0.067, and mean turn length from 4.2 to 15.5 words. A good synthetic-conversation model has to learn many local interaction regimes, not just sprinkle conversational markers evenly. A useful rule of thumb from prior work is that these interactional cues are structured, not cosmetic. Turn-taking gaps cluster near the 0-200 ms range across languages, disfluencies rise with planning difficulty, and backchannels are pervasive in real dialogue.345
CallHome is useful precisely because it is already much closer to spontaneous interaction than studio read speech. It contains 120 unscripted 30-minute English telephone conversations, and most participants called family members or close friends.12 But it is still a recorded telephone corpus, so it is best treated as an intermediate target rather than a final one.
Prompt-only dialogue generation tends to produce written-looking conversation, with interactional disfluency often landing closer to the 1-6% range while real conversational transcripts are more like 15-30%. Typical pipeline work increasingly treats synthetic and raw data as complements rather than substitutes: synthetic data cheaply expands persona, topic, and scenario coverage, while smaller amounts of real conversational data anchor the timing and dynamics that current systems still miss. Furthermore, even licensed raw corpora can still be narrow and unnatural in channel, setup, and social situation, resulting in conversational data that, as with its synthetic counterpart, lacks the same complex flow and disfluencies while also failing to represent a diverse distribution of scenarios and people. In fact, synthetic data specifically trained to generate more realistic dialogue can be instrumental in targeting the behaviors raw data corpora underrepresent, being used more as integral parts of audio datasets or better scripts for guiding raw audio generation.
What we built
The method is intentionally simple. We start with a complex transcript that preserves overlap, inline backchannels, laughter, fillers, and interruption markers. We then reduce it into the most basic backbone that preserves the overall semantic context.
Qwen is trained to undo that simplification and predict a richer conversational transcript from the cleaned version. The non-reasoning model learns this as a direct reconstruction problem. The reasoning variant is trained with additional reasoning traces that describe why certain prosodic or disfluent elements plausibly belong where they do, with the aim of encouraging more thoughtful placement.
We also varied instruction templates, target lengths, and conversation slices during training so the model saw both full calls and smaller fragments. This helps the model generalize to many types of inputs and outputs.
Main results
All systems were evaluated on the same 20-conversation held-out split. Each model received the same simplified transcript input, and every output was scored against the original CallHome complex transcript using the a shared feature extractor we built.
| Condition | Filler Density | Overlap Count | Backchannel Count | Laugh Count (A) | Complexity Ratio |
|---|---|---|---|---|---|
| Ground truth | 0.0221 | 45.20 | 15.55 | 9.80 | 2.18 |
| GPT-4o | 0.0004 | 0.00 | 1.80 | 0.10 | 0.79 |
| Qwen (fine-tuned) | 0.0212 | 15.00 | 6.05 | 3.10 | 1.02 |
| Qwen (reasoning) | 0.0236 | 19.20 | 5.35 | 5.50 | 1.12 |
GPT-4o is the cleanest writer in the generic sense, but it is the least human system in this evaluation. It almost never emits overlap. It produces nearly no fillers, almost no laughter, and a much shorter transcript than the human target. The fine-tuned Qwen models recover a much larger share of the missing conversational structure.
Human gap closed vs GPT-4o
For 7 of the 8 headline features, the fine-tuned models cut GPT-4o's error by 16% to 46%. Interruption count is the only exception, and it is sparse in this setup.
Visible signal recovery vs ground truth
Raw transcript markers tell the same story. GPT-4o mostly paraphrases. The Qwen variants recover much more of the explicit conversational structure.
Across eight headline features, the fine-tuned models are closer to human ground truth on 7 of 8 dimensions.
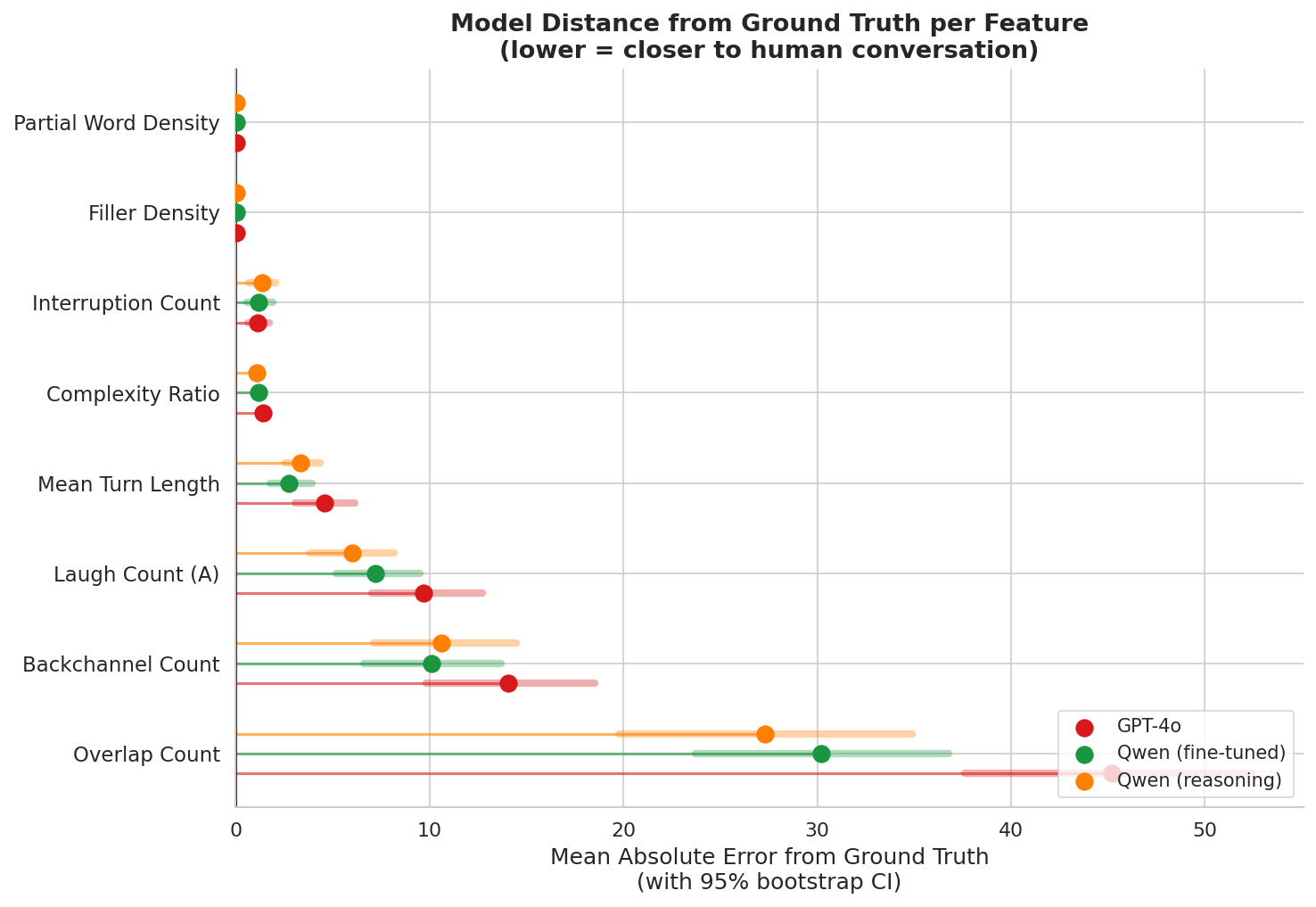
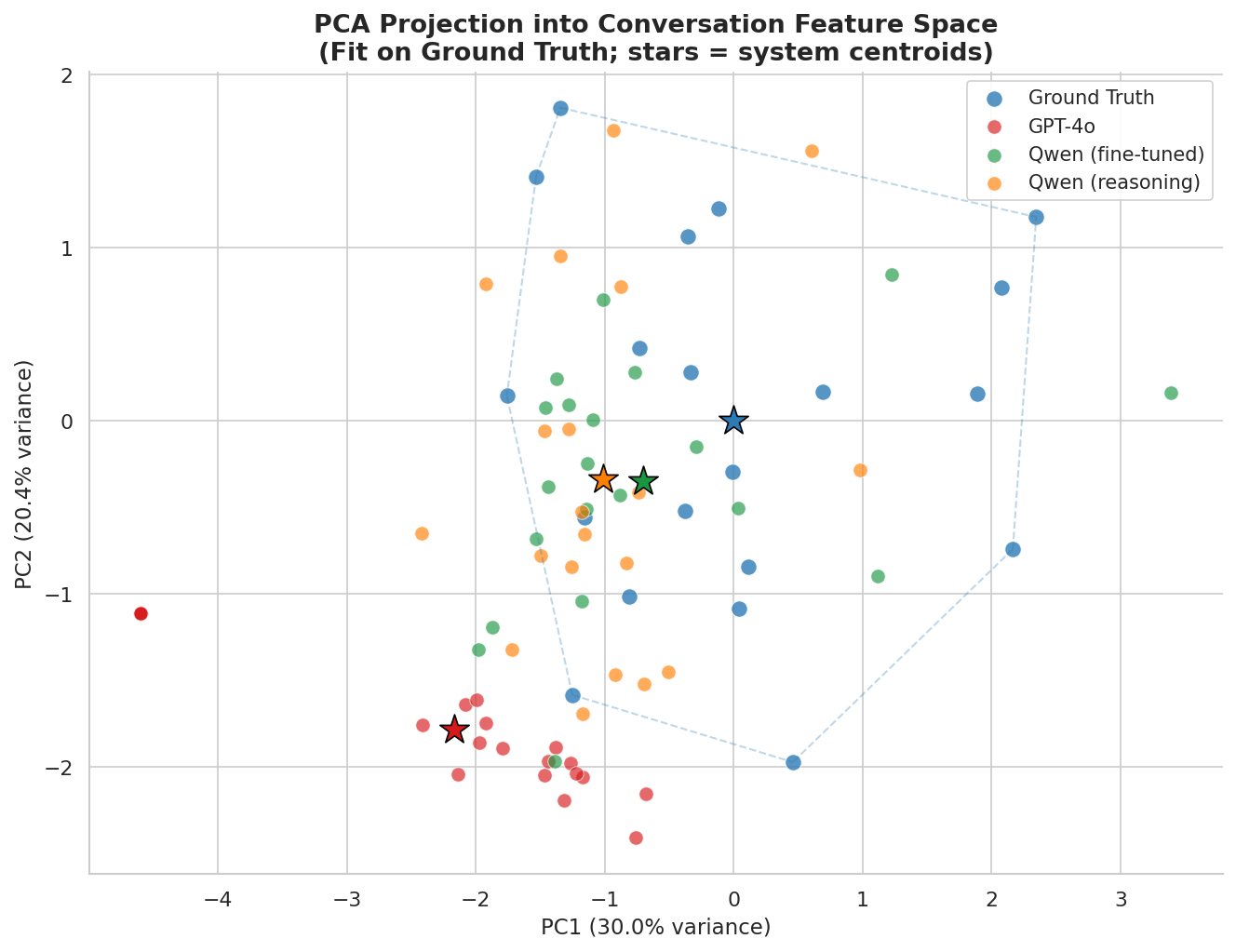
The two Qwen variants are not identical, and that split is useful rather than inconvenient. The reasoning model is the better interaction-texture model. It is closest to ground truth on filler density, overlap count, laughter, and overall complexity ratio. The non-reasoning model is often the cleaner content-preserving editor. It is closest on backchannel count, partial-word density, and mean turn length. On the composite held-out score, the reasoning model wins 11 conversations and the base fine-tuned model wins 9. GPT-4o wins none.
Analysis
GPT-4o keeps most of the content but preserves too much of the clean straightforwardness of the simplified transcript. It uses occasional fillers, but they are sparse and generic, and it still reads like edited prose. The non-reasoning Qwen moves much closer to the rambling, interruption-friendly feel of the ground truth, but it sometimes pushes too far and can blur or distort details. The reasoning model also rambles, but the placement tends to feel more grounded.
At a qualitative level, the human transcripts are often rambling, partially repetitive, and surprisingly hard to follow when stripped of audio. A lot of the meaning comes from rhythm, intonation, and timing rather than from tidy sentence structure. That is exactly why transcript realism matters for synthetic conversation.
Across the held-out set, GPT-4o tends to underuse backchannels, overlap, and interruption-like structure. It is trying to preserve coherence in a written-text sense. The Qwen models do better at recovering the slightly nonsensical texture that real conversation often has on the page. That is directionally what we want for synthetic conversational data.
The tradeoff is also visible. The non-reasoning model sometimes goes too far and can lose grip on parts of the original information. The reasoning model does not solve that completely, but it appears to ground more of the disfluency placement and makes the messiness feel less arbitrary.
Where this points
The strongest claim here is not that these models now generate human conversation perfectly. They do not.
Having been trained on a pretty small, non general corpus of data, all three evaluated models still under-generate relative to CallHome on overall transcript complexity. Even the reasoning model reaches only 1.12x output/input length against a human target of 2.18x. And some outputs still show formatting artifacts. But that should not obscure the main result.
The fine-tuned models are no longer treating spontaneous conversation as clean text plus a few random filler words. They are learning a more structural representation of interaction. That is exactly the direction synthetic dialogue data needs.
Note: This is best understood as an intermediate positive result, not a final system. Such a training paradigm can assist in the overall task of generating more realistic conversational data. However, this model is limited and not fully optimized in both the amount and breadth of data it has been trained on and the architecture it uses. This is but one prototype/step towards the synthetic pipeline we are researching at Liminal. We plan on open sourcing our training method and model weights in the future.